


What Is Vector Search?
In its simplest form, vector search (sometimes called semantic search or similarity search) is a technique that allows systems to match items not just by literal keyword overlap but by conceptual closeness. In other words, it retrieves results that are semantically similar to a query, even when the query and the stored content do not share the exact terms. Traditional keyword search is largely lexicon-based: you type words, and the engine looks for documents containing those words (or close variants). Vector search, by contrast, converts both queries and content into numerical representations (vectors) that capture meaning, context, and relationships. Then it finds vectors that are “close” in that multidimensional space, meaning they are similar in meaning, and surfaces the content associated with those vectors.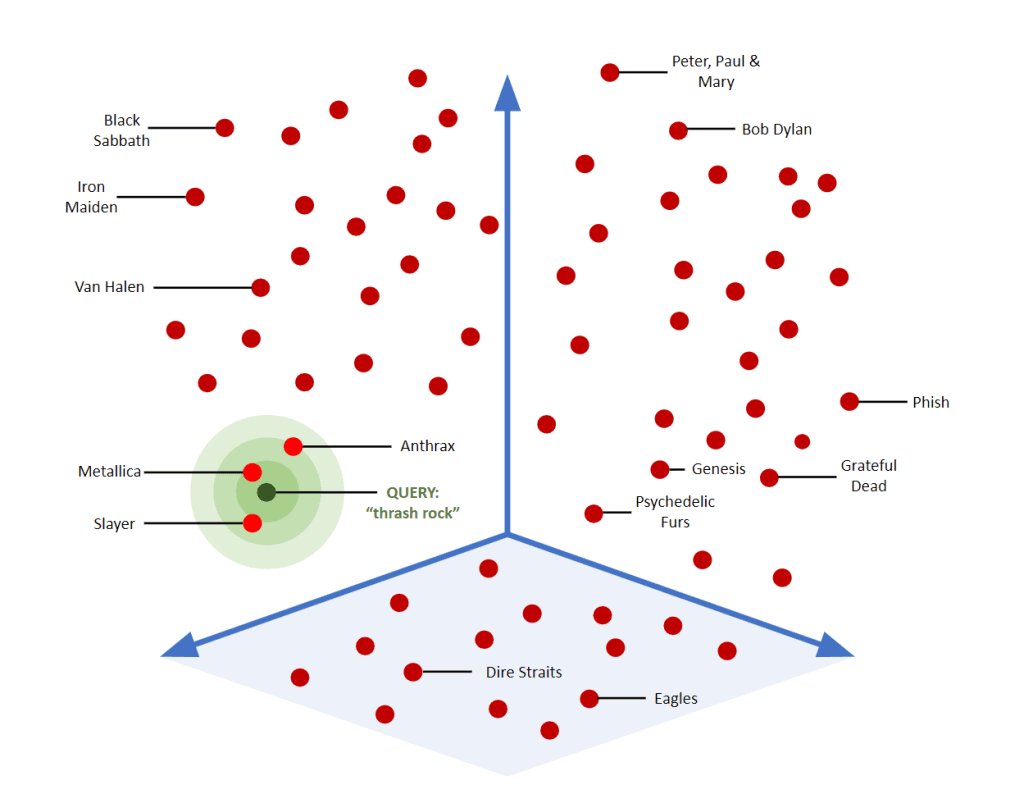
How Vector Search Works (Step by Step)
To demystify vector search, let us break down its key steps. While implementations vary, most modern vector search systems share a similar underlying architecture.1. Embedding / Vectorisation
First, you convert your content (text, images, audio) into embeddings, numerical vectors in a high dimensional space. In text, that might mean mapping a sentence, paragraph, or document into a 768-dimensional vector (or more) that captures context, semantic meaning, and relatedness. Those embeddings are generated by machine learning models (often transformer models, BERT variants or other embedding models) that have been trained to figure out semantic relationships among words and contexts.2. Indexing
Next, the embeddings are stored in a vector index (or vector database). The index is structured so that similarity searches (i.e. “which vectors are closest to a query vector?”) can be done efficiently, even over millions or billions of vectors. Because brute-force comparison of every vector against every other is computationally expensive, most systems use approximations like Approximate Nearest Neighbour (ANN) algorithms. Common options include HNSW (Hierarchical Navigable Small World graphs) or clustering plus quantisation techniques. One widely used library is FAISS (by Meta) which provides efficient similarity search and clustering algorithms.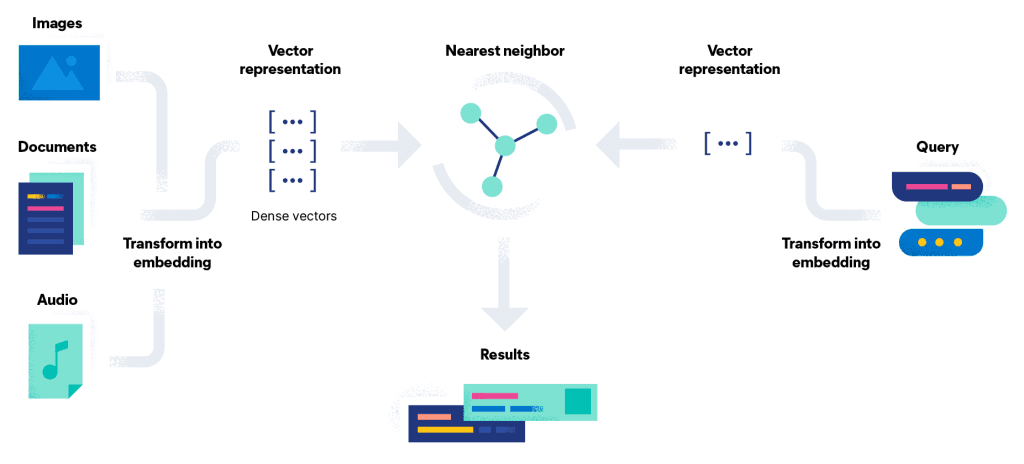
3. Query Transformation
When a user issues a search, the query text is also transformed into an embedding (in the same “space”) using the same or compatible embedding model.4. Nearest Neighbour Search
The system then compares the query embedding against the stored embeddings to find the most similar ones. Rather than exact matching, it looks for vectors within some “distance” threshold (or the top k closest) using similarity metrics (e.g. cosine similarity, Euclidean distance) to rank results.5. Hybrid / Filtering and Ranking
In many practical systems, the vector closest matches are combined (or merged) with traditional keyword / lexical matching in a hybrid fashion. This is because purely vector-based relevance sometimes needs reinforcement with lexical signals like exact matches, page authority, metadata, freshness, or other ranking signals. Additionally, vector search queries may include filters (e.g. date ranges, category codes) so results are contextually constrained. Some approaches integrate filter conditions directly into vector search, others apply them before or after similarity lookup.6. Return and Presentation
Finally, the system returns the top matched items (documents, pages, products) sorted by similarity score (possibly adjusted by other ranking signals) to the user.A Simple Example
Imagine you run a blog about sustainable travel, and you have numerous articles:- “Eco-friendly travel tips in Southeast Asia”
- “Sustainable transport alternatives in Europe”
- “Low-carbon accommodation ideas”
- “How to offset your travel emissions”
- A traditional keyword search might prioritise pages containing green, travel, ideas, Asia, exactly these words or close synonyms.
- A vector search system, however, maps both the query and all blog content into embeddings. The query embedding might lie near the embedding of “Eco-friendly travel tips in Southeast Asia” (because their topics are semantically aligned), even though that page might not use exactly “green travel ideas Asia.”
- It might also surface relevant pages like “Sustainable transport alternatives in Europe” if they share thematic overlap but perhaps demoted slightly because of geographical mismatch based on filter or hybrid ranking signals.
Why Vector Search Matters for SEO
If vector search were merely a technical curiosity, it would not interest SEOs. But in fact, it is increasingly becoming a core component of how modern search engines interpret, index, and surface content. Below are key reasons why it matters and actionable implications for SEO strategies .1. Search Is Shifting from Syntax to Semantics
Modern search engines aim to understand intent, context, and conceptual meaning, not just match keywords. Vector search helps bridge the gap between how users think and how content is written. As users ask more natural language queries (e.g. voice search, conversational queries via chatbots), the reliance on semantic matching will only increase.2. Better Handling of Synonyms, Ambiguity, and Variation
One of the recurrent frustrations in SEO is that content might be highly relevant to a searcher’s intent but fail to rank because it uses different wording. Vector search mitigates this. For example, “automobile,” “car,” “vehicle,” “EV” may be conceptually near each other in embedding space. It also helps with misspellings, partial matches, or queries that use vague or ambiguous terminology, the embedding captures meaning, not just token overlap.3. A Foundation for “Semantic SEO”
More SEOs are talking about semantic SEO , crafting content that covers related entities, subtopics, and context depth, because search engines increasingly judge content on topical comprehensiveness. Vector search offers the infrastructure that makes such richness interpretable. In practice, content that addresses multiple sub-aspects of a topic (e.g. definitions, use cases, comparisons) is more likely to map closely in embedding space to user queries covering those aspects.4. Internal Linking, Content Clustering and Relevance Modelling
SEO practitioners are already experimenting with using embeddings to discover semantically similar pages (for internal linking), detect content gaps , or cluster content around themes. By building a map of semantic similarity across your own site, you can structure your content to strengthen topical authority and make “neighbouring” pages more discoverable.5. Hybrid Search, Retrieval Augmented Generation and Enhanced Experience
Some search systems (including major ones) implement hybrid search, combining vector similarity with lexical matches and other ranking signals to deliver balanced results. Moreover, vector search plays a role in retrieval augmented generation (RAG) where large language models use embeddings to fetch relevant content from domain knowledge before constructing answers. This has ramifications for how search engines surface answers, featured snippets , or AI-assisted results.6. Competitive Differentiation
If many publishers simply focus on keyword optimisation, those who embrace richer semantic approaches (and tailor their content to be embedding-friendly) may gain an edge, especially as the search engines’ internal models mature. As one SEO commentator warns, optimising only for vector search without thinking carefully can be risky, but ignoring it entirely risks falling behind.Practical Tips for SEO with Vector Search in Mind
You don’t need to become a machine learning expert to prepare your SEO strategy for the vector search era. Below are actionable steps and principles you can begin applying today.1. Focus on Depth and Coverage
Instead of writing shallow content that repeats keywords, aim to cover related subtopics, definitions, use cases, comparisons, and user questions. This breadth helps your content be closer in embedding space to diverse queries.2. Use Related Entities, Synonyms, and Variants
Incorporate synonyms, related terms and entity mentions (brands, tools, dates, locations) naturally. This enriches semantic signals. For example, if your topic is “solar panels”, also mention “photovoltaic modules”, “PV systems”, “renewable energy”, etc.3. Structure Content with Clear Sections
Well-structured articles (with headings, summaries, lists) help embedding models capture semantic boundaries. Use subheadings that reflect conceptual shifts (e.g. “benefits”, “drawbacks”, “implementation steps”).4. Internal Linking via Semantic Similarity
Use embedding-based tools or services (or early SEO tools that expose embeddings) to find pages on your site that are semantically close to each other. Link them meaningfully. This strengthens topical relevance and helps search engines understand your site structure semantically.5. Leverage Hybrid Strategies
Do not abandon keyword signals. Continue to optimise for relevant keywords and metadata (title tags, meta descriptions, headings). But layer on semantic richness and topical depth as complementary signals.6. Monitor Performance via Query Insights
As search consoles and analytics tools evolve, monitor which queries lead traffic, and inspect whether your pages are surfacing for related but non-exact match queries. Adjust content to close embedding distance to those queries.7. Experiment with Embedding Tools (for advanced SEO teams)
If your team is comfortable with APIs or light ML work:- Generate embeddings for your top content and map them to query embeddings
- Use vector databases (e.g. Pinecone, Weaviate) to cluster content and detect “outliers”
- Use those insights to identify content gaps or “orphan pages” (pages semantically distant from clusters)
- Use Screaming Frog’s JS extraction to pull embeddings during crawl for analysis.
Challenges, Cautions and Future Outlook
While vector search brings exciting possibilities, it is not a panacea. Be aware of these caveats and challenges:- Model biases and errors: Embeddings can reflect biases in training data, leading to flawed matches or omissions.
- Interpretability: Unlike keyword matches, it can be harder to explain why a piece of content was matched.
- Over-optimisation risk: Trying to “write for vector search” in a forced or unnatural way may backfire. As one SEO thought leader warns, Google’s representatives have indicated that knowing about vector search doesn’t grant a shortcut to rankings.
- Computational cost: Generating and indexing embeddings over large content bases requires infrastructure, and handling vector search at scale is nontrivial.
- Rapid evolution: Embedding models and ranking algorithms evolve quickly; what works today may require adaptation tomorrow.



